12月3日,中央民族大学56创孵化项目大学生创业团队——巨神人工智能科技,发布全球首套藏文手写体数字数据集TibetanMNIST,并在国内领先的数据科学平台科赛网独家首发。这个学生创新团队曾于今年6月被评为“北京地区高校优秀大学生创业团队”。
图为TibetanMNIST的数据样本。图片由才让先木提供。
什么是MNIST?
图为MNIST 数据集。图片由才让先木提供。
MNIST数据集简而言之就是一个手写数据识别库,包含有大量的手写数字图像,可以用来识别各种手写体数字。MNIST 数据集来自美国国家标准与技术研究所, 由Yann LeCun教授主导建立。该数据集由250个不同人手写的数字构成, 这250个人中50% 是高中学生, 50% 来自人口普查局的工作人员。该数据集共包含70000张数字图像,其中训练集60000张,测试集10000张。自MNIST数据集建立以来,被广泛地应用于检验各种机器学习算法,测试各种模型,为机器学习的发展做出了不可磨灭的贡献。
用它做什么?
据团队负责人袁明奇同学介绍,现在很多人都用过触屏板手机或电脑的手写功能,每个人都有自己的书写风格,那么当我们写下数字之后,如何让计算机成功地识别呢,我们可以通过机器学习的方法来解决这个问题,如使用卷积神经网络模型,模型的结构如下所示: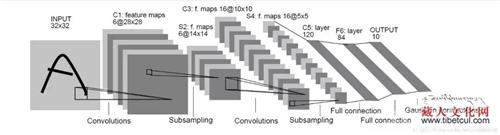
图为LeNet5卷积神经网络模型结构。 图片由才让先木提供。
通过输入MNIST数据对模型进行训练,最终会获得一个可识别手写体数字的网络模型,这就为计算机识别手写体数字提供了一种很棒的方法。MNIST数据集的生命力极其旺盛,自其建立以来,在其基础上衍生出了更多的变式,如FashionMNIST,它们都给出了不俗的表现。
将民族文化融入机器学习
“在一次会议上,我无意间看到了一位藏族伙伴的笔记本上写着一些奇特的符号。他告诉我,这些是藏文数字,这对于从小使用阿拉伯数字的我十分惊讶,这些奇特的符号竟有如此特殊的含义!我当时就产生了一个想法,能不能让计算机也能识别这些数字呢?”袁明奇告诉记者,“当时想法很简单,就是希望将少数民族文化融入到机器学习中。”
“这个想法得到了大家的一致认可,于是我们开始模仿MNIST来制作这些数据,由于对藏文的不熟悉,一开始的工作十分艰难,直到取得了藏学研究院同学的帮助,才使得制作工作顺利完成。历时1个月,超过300次反复筛选,最终得到17768张高清藏文手写体数字图像,形成了TibetanMNIST数据集。”谈起那一个月的工作,团队成员纷纷表示“累并快乐着”。
藏文作为我国的少数民族文字之一,具有十分悠久的文化历史,而藏文文字独特的书写方式和构造,使得其极具美感!藏文主要有楷体和行体两种书法体,此次创新团队制作的TibetanMNIST正是行体藏文中的数字,如下图所示: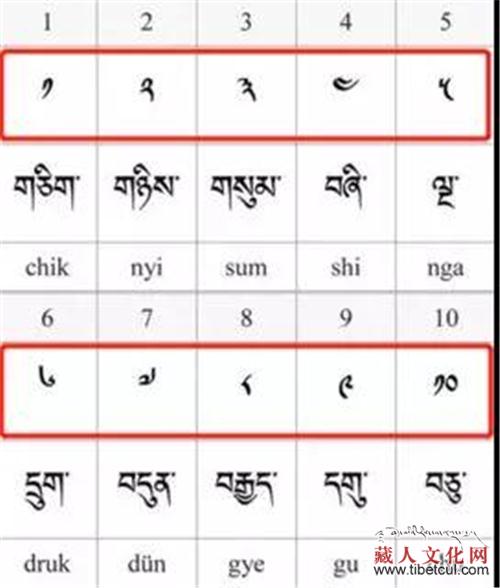
图为形体藏文、楷体藏文、拉丁文以及阿拉伯数字的对照表。图片由才让先木提供。
不忘初心,开源共享
“我们也没有想到这个项目会有那么多人关注,现在有很多人跟我们联系,表示对这个项目感兴趣。”袁明奇对自己团队取得的工作成果感到骄傲。“但是,这只是万里长征第一步,我们需要更多的图像数据,不断对算法进行优化,才能保证这个识别模型的精密程度。而且,现在只是藏文数字数据集方面有了进展,后期我们还要做藏文字母手写体数据集等一系列更加复杂的数据。距离实际的应用阶段,我们还有很多工作要做。”
图为团队主要负责人在谷歌开发者社区活动现场。图片由才让先木提供。
面对突如其来的关注,这群身怀人工智能梦想的95后学生团队,做出了一个让人惊叹的举动,“我们并没有想过利用这个项目挣钱,这不是我们的初衷,所以经过反复商议,我们决定将其完全开源,供所有的开发者自由使用,这样才能使其能发挥最大的价值!”

